#kubernetes
#helm
#prometheus
#grafana
#terraform
Article publié le 4 févr. 2022
·14 min de lecture
Nous allons voir ensemble pour déployer toute une stack de télémétrie sur un cluster Kubernetes, avec de l’Infra as Code.
Dans ce blog, nous allons voir ensemble les points suivants :
- Créer un cluster Kubernetes sur OVH
- L’automatisation avec Terraform et Helm
- L’installation et le paramétrage de Prometheus
- L’installation et le paramétrage de Grafana
- L’installation de nos premiers dashboards
Génération des clés API d’OVH
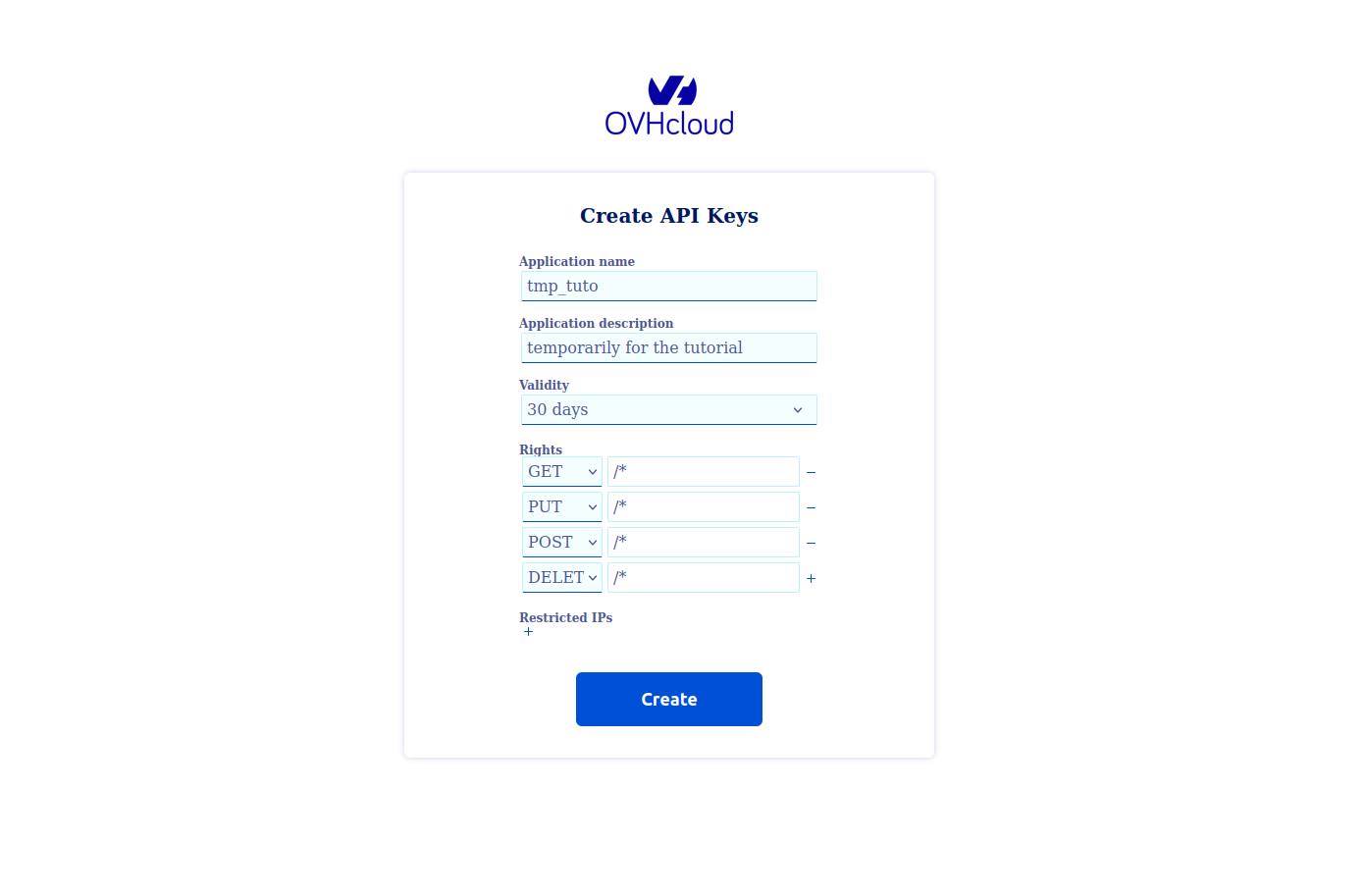
Pour commencer, nous allons devoir créer nos clés API d’OVH. Cela nous permettra de créer et manager nos clusters Kubernetes directement depuis terraform. Pour cela nous allons nous rendre sur la page de création de token d’OVH:
- Donner un nom à votre application et une description.
- Donner une date expiration.
Et très important, nous allons préciser les méthodes et les routes que nous aurons le droit d’utilisées:
Nous allons obtenir 3 clés à conserver précieusement :
- Application key (AK)
- Application secret (AS)
- Consumer key (CK)
Terraform
Maintenant que nous avons généré nos clés API, nous allons passer à la partie Infrastructure as Code (abrégé IAC) avec l’outil Terraform. Terraform est un outil créé par la société Hashicorp, à partir de cette application, nous allons pouvoir communiquer et agir avec notre infrastructure très facilement.
⭐️ IAC ou Infrastructure as Code: permet de configurer, gérer et déployer des infrastructures à partir du code, l’intérêt est multiple et les avantages certains. Grâce à l’IAC, nous allons diminuer les erreurs humaines puisque nous allons pouvoir scripter et uniformiser notre manière de déployer. Nous allons aussi pouvoir garder une trace de toutes nos modifications sur l’infrastructure et le travail en équipe sera très facilité en utilisant un outil de versioning comme
git.
Téléchargement et installation de Terraform
Nous avons plusieurs méthodes pour installer terraform, on peut se rendre sur la page de téléchargement et prendre la version pour notre système d’exploitation. Juste à suvire les indications pour faire l’installation, ce qui consiste généralement dans le téléchargement d’un binaire.
Ici, on propose une autre façon de faire, en passant par l’outil tfswitch. Cet outil permet de gérer plusieurs versions de terraform en même temps sur son poste de travail et de pouvoir passer d’une version à l’autre très aisément.
Sur Linux nous pouvons exécuter cette commande pour l’installer:
curl -L https://raw.githubusercontent.com/warrensbox/terraform-switcher/release/install.sh | bash
Une fois installé, nous pouvons choisir notre version de terraform:
tfswitch
💡 C’est lui qui s’occupera de télécharger et d’installer la version de
terraform.
Nous pouvons vérifier la bonne installation de terraform:
terraform --version
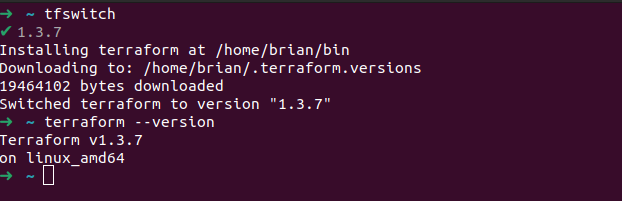
⭐️ Pour ce tutoriel, nous utilisons la dernière version actuellement la
1.3.7
Architecture des fichiers Terraform
Nous allons mettre en place une architecture de dossiers “prod-ready”, même si ce tuto est simple et centré sur les outils de télémétrie. Nous allons quand même déployer comme si nous étions dans une situation de production un petit peu simplifié.
Définissons notre backend Terraform
Terraform va stocker tout ce qu’il fait dans un fichier appelé tfstate, qu’on peut laisser en local. Mais si on veut travailler en équipe, il faut que ce fichier soit partagé pour que les membres de l’équipe puissent avoir le même état de l’infrastructure.
Pour visualiser,on peut prendre comme exemple une base de données. L’objectif serait de partager cette base de données pour que tous les membres de l’équipe puissent récupérer ou modifier les mêmes données.
Nous allons donc utiliser le concept de backend (c’est tout simplement l’endroit où sera stocké ce fichier) et utiliser un stockage Third Party comme les object storage d’OVH pour stocker et partager ce fichier.
💡 Nous pourrions utiliser d’autre système pour stocker le
tfstate.
Arborescence du dossier Terraform
Voici à quoi va ressembler notre arborescence finale de nos fichiers pour terraform:
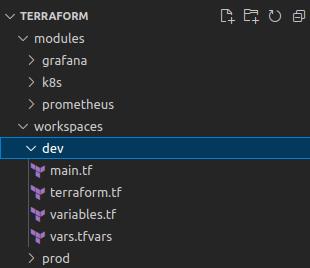
- Nous avons un dossier
module, dedans nous allons stocker notre collection de configurations standardisées pour déployer un type d’outil ou d’instance, plus généralement des ressources que nous avons besoin dans notre stack d’infrastructure. - Dans le dossier
workspace, nous allons stocker nos différents environnements. - Ensuite, nous avons notre fichier
main.tfetvariables.tfce sont les fichiers de bases pour utiliserterraform.
Mise en place
Mettons en place la configuration pour notre backend héberger sur notre stockage OVH. Pour cela nous dans le fichier terraform.tf nous allons ajouter la configuration de notre backend:
terraform {
required_version = ">= 1.3.0”
backend “s3” {
bucket = “terraform-k8s”
workspace_key_prefix = “workspace”
key = “tfstate.tf”
endpoint = “https://s3.gra.io.cloud.ovh.net/"
region = “gra”
skip_region_validation = true
skip_credentials_validation = true
}
required_providers {
ovh = {
source = “ovh/ovh”
}
kubernetes = {
version = "= 2.13.0”
}
}
}Création du bucket Terraform
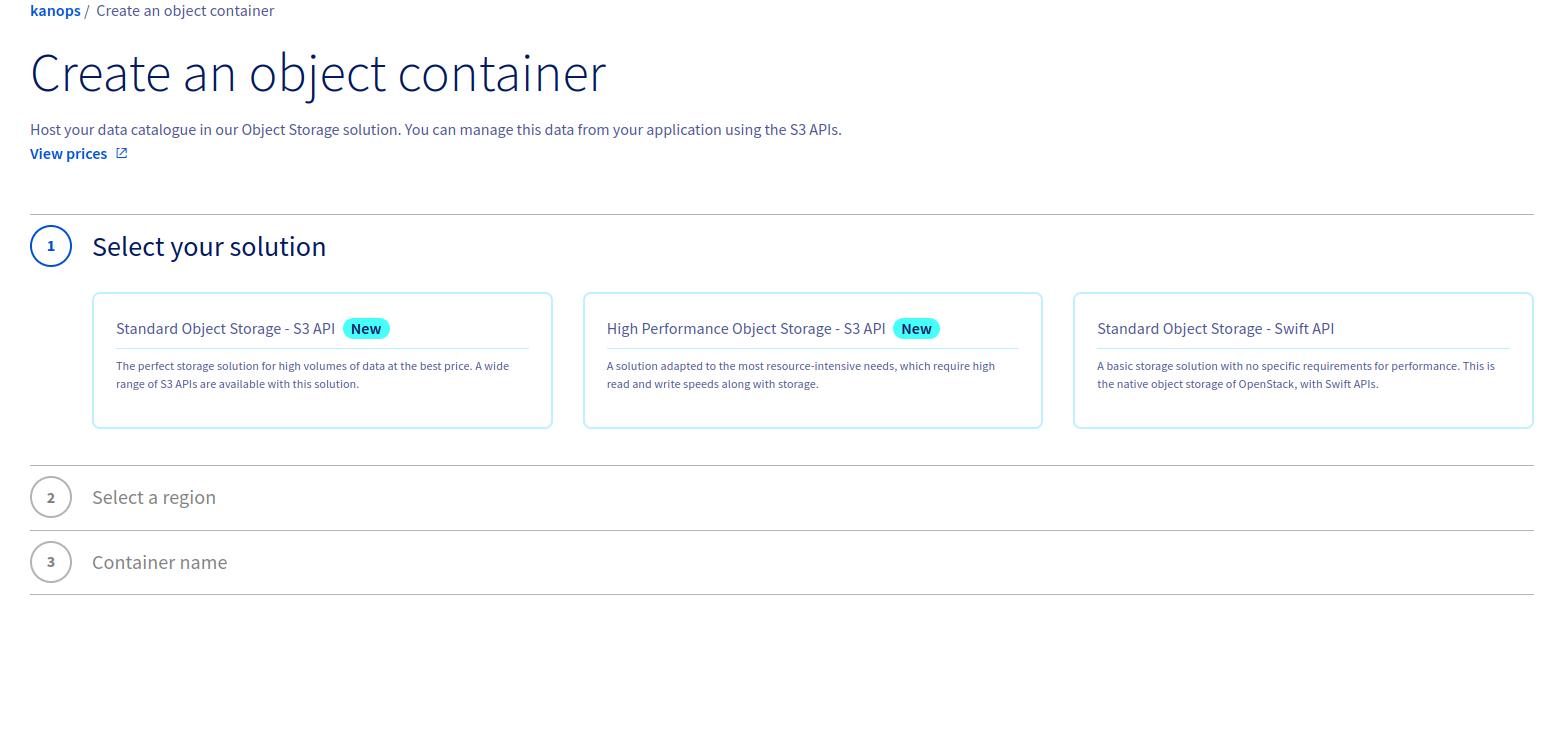
Nous allons créer à la main le bucket qui stockera notre tfstate terraform, pour cela nous allons nous rendre sur notre interface OVH dans le menu object storage et créer un bucket S3:
Ensuite, nous allons créer un utilisateur S3, qui pourra se connecter sur ce bucket:
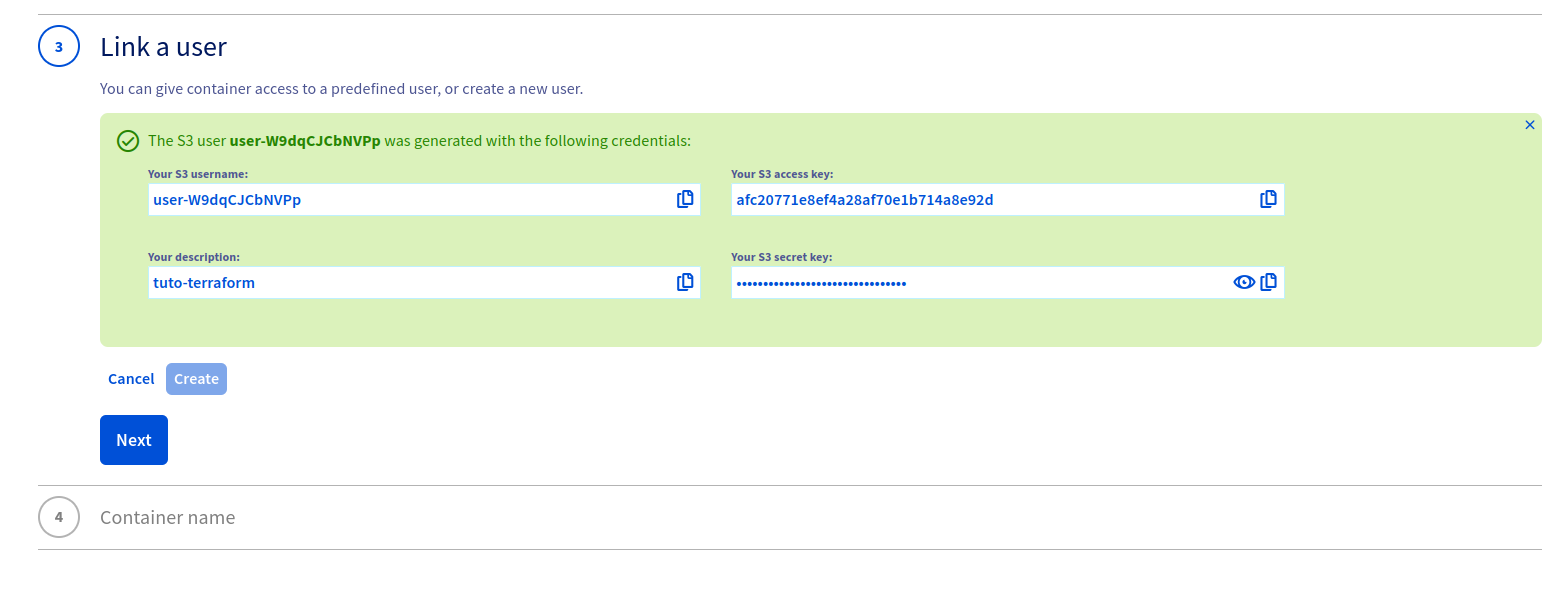
⭐️ Récupérer les clés qui seront générées pour permettre à
terraformde se connecter sur lebucket.
Donner un nom au bucket et le créer, notre nom de bucket ici sera terraform-k8s. C’est le même qui figure dans le fichier terraform.tf dans le dossier workspace/dev:

Ajout du module dans Terraform
Nous allons créer un module appelé k8s qui nous servira à créer notre cluster ainsi que les noeuds attachés à ce cluster, bien sûr grâce à ce module, la création du cluster sera dynamique:
Nous allons créer aussi un fichier output pour pouvoir récupérer le kubeconfig, ce qui nous servira par la suite pour installer notre stack de télémétrie:

Ensuite voici à quoi ressemble notre fichier main.tf et notre fichier variable.tf:
Une fois notre module k8s créer, nous allons pouvoir faire appel à ce module depuis nos différents environnements.
Retournons dans le dossier workspace/dev, dans le fichier main.tf et ajoutons le code suivant:
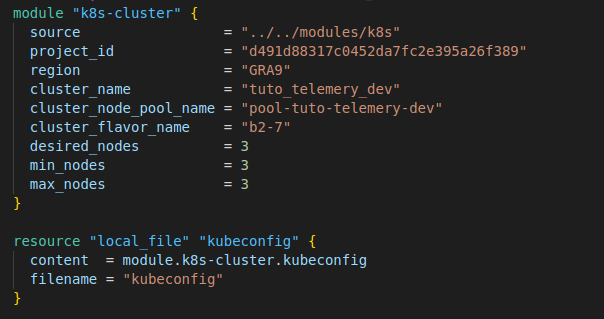
💡 Dans ce tutoriel, nous allons créer un petit serveur
kubernetespour des besoins de production un cluster avec plus de ressources est recommandé.
Maintenant on peut exécuter les commandes suivantes:
terraform init
terraform apply
Nous verrons dans l’output du terminal ceci:
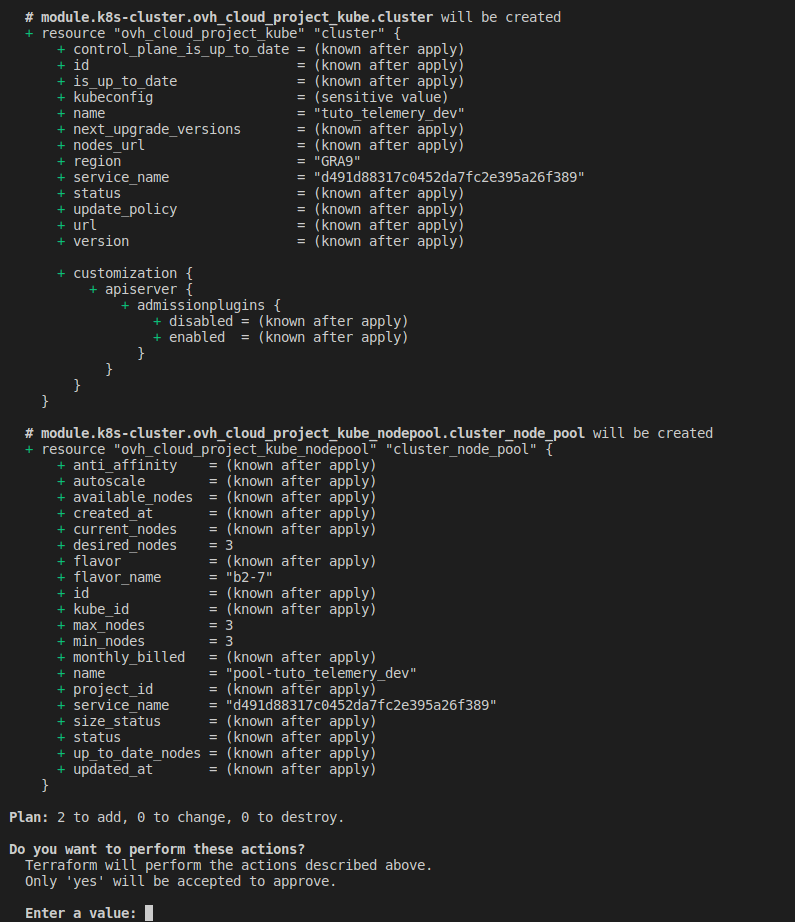
⭐️ Nous devons confirmer la création des ressources.
Nous pouvons nous connecter sur OVH pour voir que notre cluster a bien été créé avec les configurations que nous lui avons données:
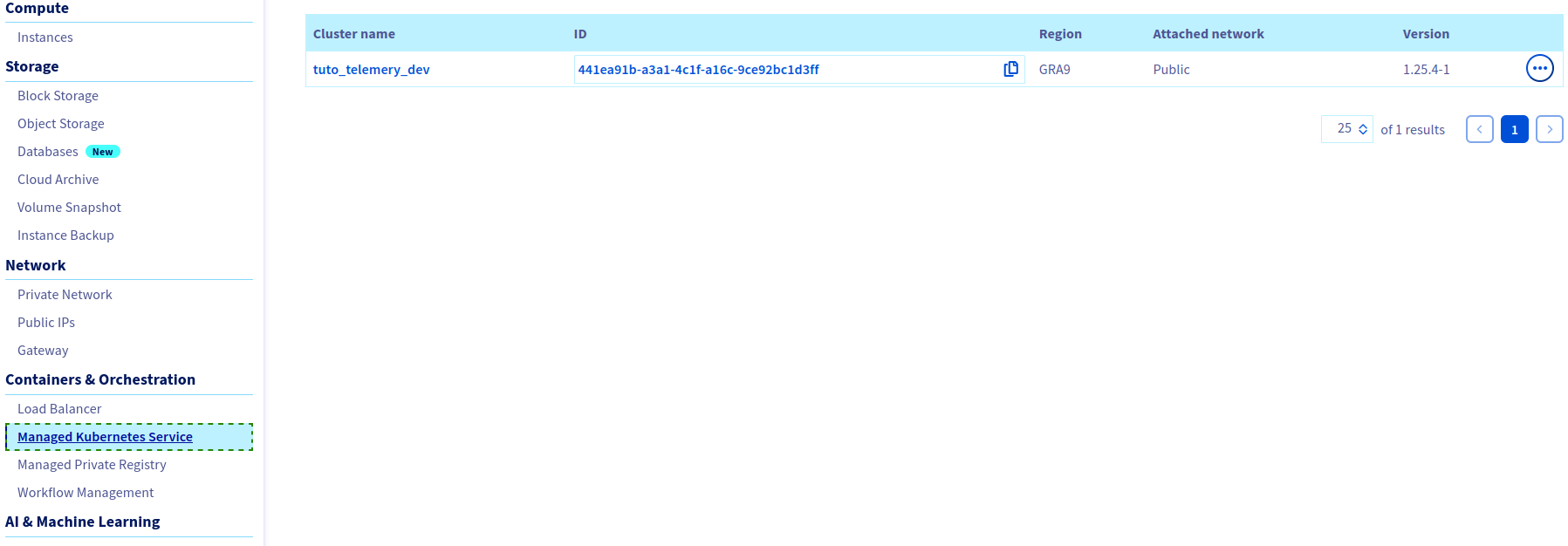
Nous avons aussi créé le fichier
kubeconfigen local, cela nous permettra plus tard de communiquer avec notre clusterk8s:
💡 Solicitez un de nos experts kubernetes, pour le conseil et la mise en place d’infrastucture as Code pour vous !
Connection à notre cluster Kubernetes
Maintenant que nous avons créé le cluster kube, nous pouvons nous connecter pour voir ce qui se passe dessus. Il existe plusieurs outils pour se connecter et communiquer avec notre cluster, dans ce tutoriel, nous allons parler de l’outil kubectl l’utilitaire de base et k9s qui est un outil vraiment incroyable que je pense indispensable pour administrer un cluster k8s.
Installation de kubectl
Le plus simple, c’est de se rendre sur la page officielle de kubernetes et de suivre les instructions selon votre système d’exploitation. Une fois installé, nous pouvons faire un petit test de connexion à notre cluster, en listant tous nos pods dans le namespace kube-system
kubectl --kubeconfig=kubeconfig get -n kube-system pods
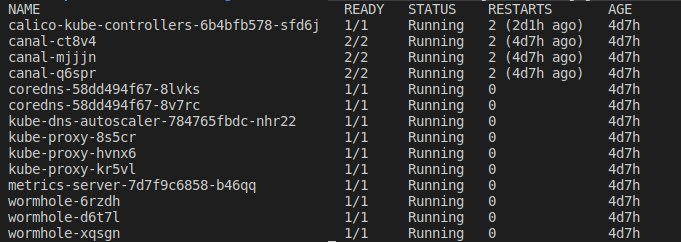
Installation de k9s
Une nouvelle fois, je vous renvoie à la page officielle de l’outil pour faire l’installation. Voici la démarche pour les utilisateurs Linux.
⭐️ Il faudra télécharger l’outil sur cette page, on prendra la version amd64.
Décompresser et le déplacer dans votre dossier avec les commandes suivantes:
tar -zxvf helm-v3.10.2-linux-amd64.tar.gz
sudo mv k9s /usr/local/bin/k9s
Un petit test pour vérifier que l’installation c’est bien déroulé:
k9s --version
Une fois l’utilitaire installé, nous pouvons nous connecter sur notre cluster:
k9s --kubeconfig=kubeconfig
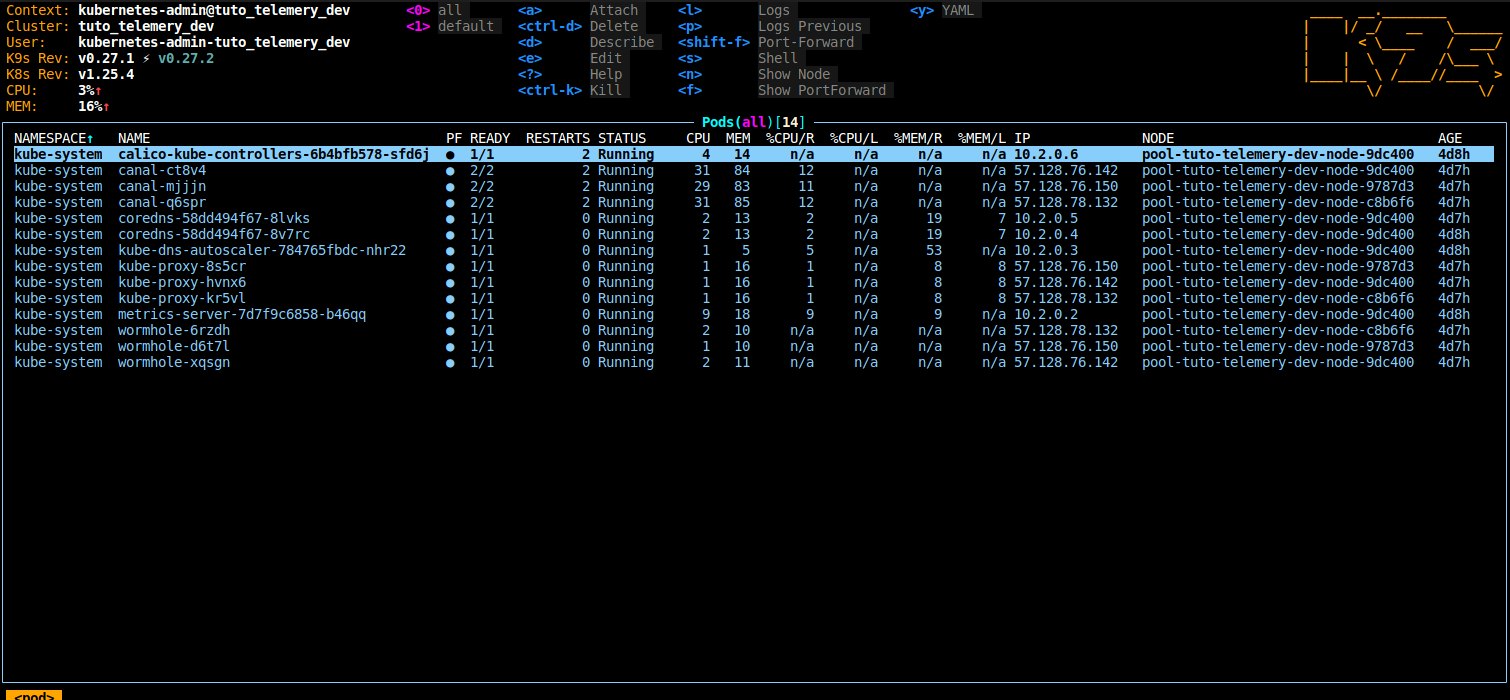
Installation de Helm
Nous allons utiliser Helm pour la configuration des différents outils dans notre cluster.
⭐️
Helmest un outil pour la gestion des packages d’applications sur Kubernetes, facilitant le déploiement, la mise à jour et la gestion des applications. Il utilise des fichiers appeléschartspour décrire les applications et leur dépendance.
Nous allons ainsi utiliser des helm chart créer par la communauté ou par les éditeurs pour déployer les outils dans notre stack de télémétrie.
Pour la partie IAC, nous allons utiliser le provider helm pour terraform, mais nous allons aussi installer le client helm sur notre poste pour nous faciliter la gestion et vérification de nos déploiements.
Pour faire cela, nous allons rendre sur la page officielle de helm.
Configuration de la stack de télémétrie
La télémétrie est un système de suivi des données qui mesure les performances et les événements d’une infrastructure et d’une application. Les données collectées incluent des métriques telles que les temps de réponse, les erreurs, les utilisations de ressources et les événements spécifiques à l’application. Cela aide les équipes informatiques à surveiller l’état et les performances de l’application en temps réel, à détecter les problèmes rapidement et à améliorer les performances.
Nous allons voir ensemble toute une stack pour mettre en place de la télémétrie dans notre cluster. Nous n’allons pas rentrer dans le détail pour chaque outil, car cela demanderait plusieurs articles pour décrire toutes les configurations possibles.
Dans cet article, nous allons surtout les outils de base pour commencer à mettre en place une stack de télémétrie, et avec une petite configuration très simple avec terraform pour la partie infra as code ou IAC.
Configuration et installation de Prometheus
Prometheus est une base de données NoSql performante pour les infrastructures distribuées. Il stocke les métriques en utilisant une base de données à structure Time Series, permettant de faire des requêtes efficaces pour l’analyse de données temporelles.
Prometheus nous servira de base de données pour stocker tout type de métrique que ce soit :
- Des métriques liées aux applicatifs: par exemple si nous avons un système d’envoi d’email, nous pourrions stocker des métriques sur le nombre d’emails envoyés.
- Des métriques sur l’infrastructure: tel que l’usage CPU, RAM disque ou bien d’autres informations.
Configuration dans Terraform
Nous allons créer un module appelé prometheus qui contiendra la configuration:
Ici la configuration de prometheus :
- La variable
server.retentionpour donner le temps de conservation des données dans la base deprometheus. - La variable
server.statefulSet.enabledàtruec’est le type de déploiement recommandé lorsque l’on utilise des bases de données. - La variable
server.persistentVolume.enabledàtrueon active la persistance des données sur disque ainsi même si notre pod redémarre, nous n’allons pas perdre de données. - La variable
alertmanager.enabledàfalsepour le moment, nous désactivons le système d’alerte, nous verrons cela dans un prochain blog.
Si nous utilisons k9s maintenant pour voir notre cluster, nous voyons notre nouveau namespace monitoring et la stack prometheus d’installée.

💡 Ici par défaut dans le
chart helmdes exporters sont installés.
Les exporters Prometheus sont des programmes tiers qui permettent de collecter des métriques depuis des sources de données externes (par exemple, systèmes d’exploitation, applications, services réseaux) et de les exposer dans un format compatible avec Prometheus. Cela permet à Prometheus de surveiller des ressources qui ne peuvent pas être surveillées directement.
Nous avons ici deux exporter qui sont installés :
node-exporter: permet de récupérer des informations liées à la machinehostainsi, nous aurons accès aux informations de disque, RAM, CPU, network, etc…kube-state-metrics: permet de récupérer des métriques liées à kubernetes par exemple le nombre de pod, de namespace, etc…
Configuration et installation de Grafana
Grafana c’est la partie graphique de notre stack, c’est un outil open-source de visualisation et d’analyse de données. Il permet de créer des tableaux de bord personnalisés pour surveiller les performances et les métriques d’infrastructures et d’applications, et offre une large variété de sources de données pour les connecter. Pour l’installation de Grafana, nous allons créer un nouveau module appelé grafana.
Ci-dessous le contenu du fichier main.tf:
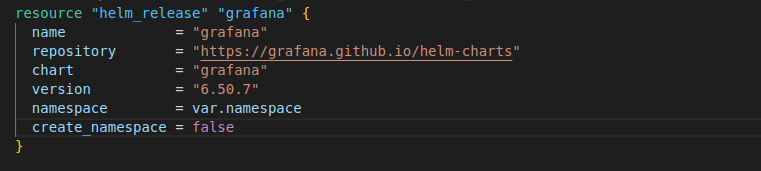
Nous ajoutons ensuite l’appel du module dans notre fichier main.tf pour l’environnement dev dans le dossier workspace:
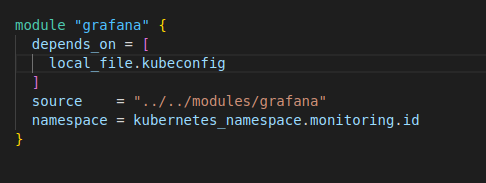
Nous exécutons de nouveau notre fichier terraform dans le dossier workspace/dev:
terraform apply
Et lorsque l’installation est terminée dans k9s, nous pouvons voir notre pod grafana:

Nous allons maintenant faire un portforward pour créer une connexion depuis notre ordinateur en local au Grafana sur notre cluster qui se trouve chez OVH. Avec l’outil k9s c’est très facile, il suffit de se placer sur le pod grafana et de faire shift-f ensuite garder les sélections de port par défaut et appuyer sur la touche entrée.
Maintenant, nous pouvons ouvrir notre navigateur et aller sur l’adresse localhost:3000 pour atteindre la page login.
💡 L’utilisateur par défaut est
adminet pour récupérer le mot de passe par défaut voici la commande:kubectl --kubeconfig=kubeconfig get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
Une fois fait, nous arrivons sur la page d’accueil de grafana:
À présent, nous pouvons configurer notre base de données prometheus pour que grafana puisse s’y connecter.
Pour cela nous allons dans la navigation de gauche configuration => datasource => add data source:
Nous allons choisir comme type de source de données Prometheus.
Et ensuite, nous rentrons dans le champ url la valeur suivante : prometheus-server.
⚠️ Dans notre
helm chart prometheus, un service est créé par défaut sur le port 80, mais si ce n’est pas le cas, il faut vérifier le service prometheus dans le cluster k8s.
Attention si votre prometheus se trouve dans un autre namespace suffixé l’url par le nom du namespace comme cela prometheus-server.<namepsace_prom>:
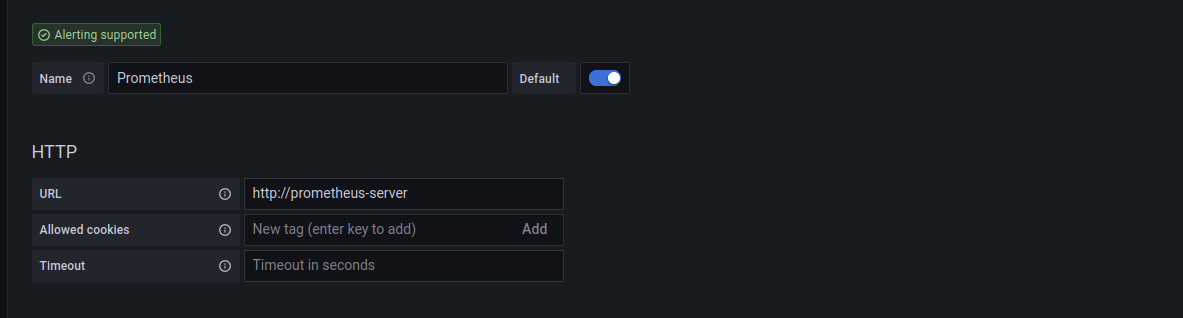
Nous sauvegardons et un petit message nous dit que la configuration est correcte:
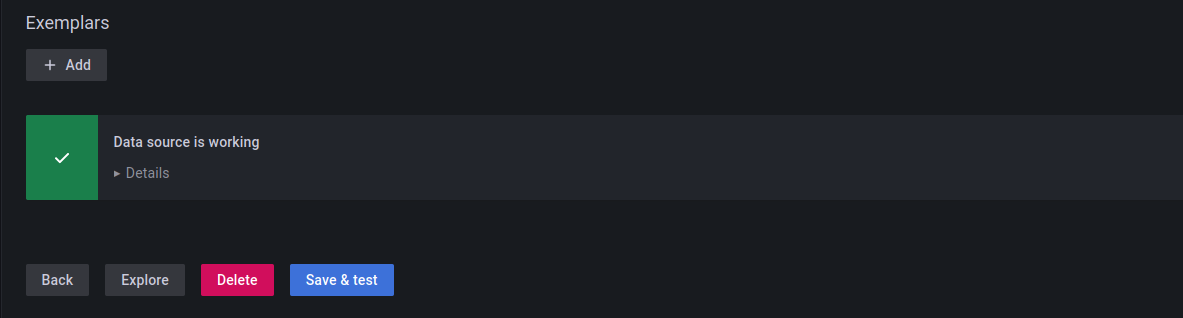
Intégration de nos premiers dashboard dans Grafana
Nous allons récupérer des dashboards déjà créer et partager par la communauté. Étant donné que dans le helm chart de prometheus, il installe par défaut 2 exporter node-exporter et kube-metric-exporter, nous pouvons installer des dashboards qui utilisent ces métriques.
Le dashboard pour node exporter est proposé directement par Grafana ici.
Pour l’installer dans notre Grafana, nous allons dans le menu dashboard et nous choisissons import, nous rentrons l’id du dashboard pour node-exporter:
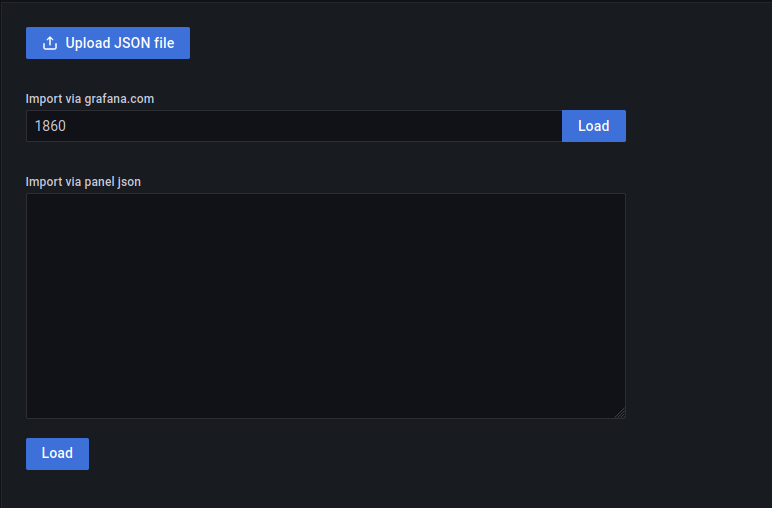
Nous choisissons un nom pour notre dahsboard, un dossier et surtout la base de données prometheus, que nous avons configurée plus tôt et on importe:
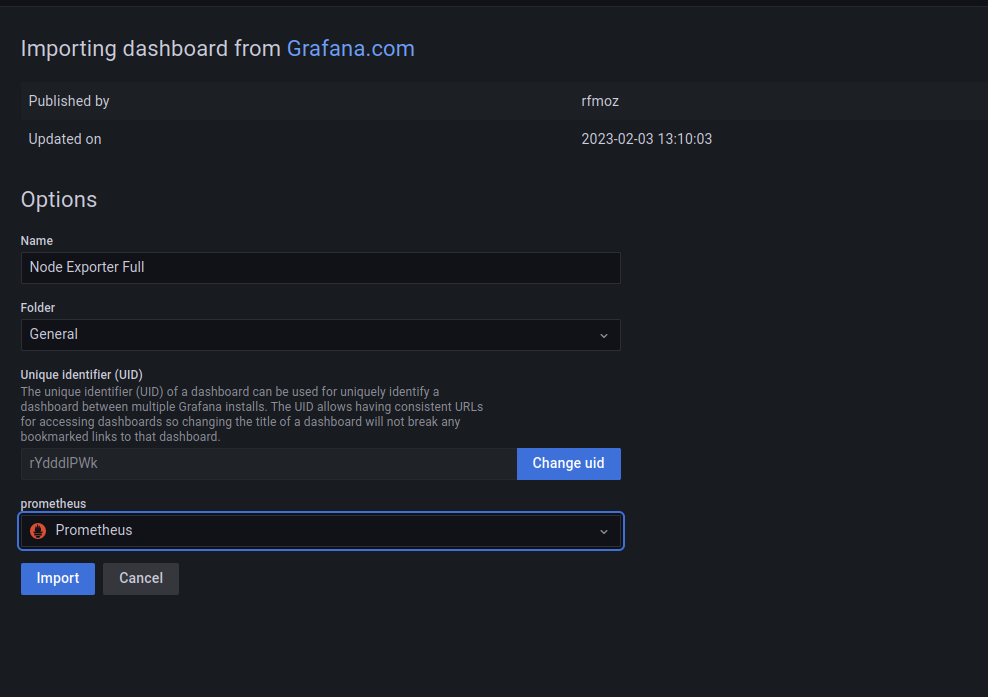
Et nous arrivons directement sur le dashboard:

Nous allons importer un dashboard pour utiliser les données que l’exporter kube-metric nous propose sur cette page. Nous récupérons l’id (par exemple le 15757) et nous faisons la même manipulation que pour notre premier dashboard:
Nous allons nous arrêter ici, dans ce premier blog. Nous avons vu ensemble comment créer un cluster kube sur le provider OVH à partir de terraform et installer notre premier stack pour la télémétrie.
En conclusion, la mise en place de la télémétrie dans un cluster Kubernetes à l’aide de Prometheus et Grafana est un moyen efficace pour surveiller et visualiser les performances et la santé du cluster. Les deux outils travaillent ensemble pour collecter les métriques et les afficher de manière claire et conviviale pour une analyse rapide et une prise de décision plus éclairée.
💡 Retrouvez toutes nos prestations, si vous souhaitez être accompagnés par des architectes Kubernetes pour mettre en place une stack complète de monitoring et d’alerting sur un cluster Kubernetes.

Brian BENOIT
Brian est un expert en infrastructure Cloud et fondateur de Kanops, mais avant tout un passionné de l'informatique. Il a su construire et livrer des plateformes performantes et robustes. Solidement ancré dans la philosophie Devops, il propage la bonne parole pour augmenter la productivité des équipes, il est aussi très investi dans l'open source car les meilleurs outils sont partagés et distribués librement.